
Notepad++ ist ein kostenloser Texteditor. Er unterstützt verschiedene Programmiersprachen, um Quelltext einfach zu bearbeiten. Ähnlich wie in Entwicklungsumgebungen erfolgt der Einsatz von typografischen Mitteln. Dies bedeutet, dass der Text in seinem Aussehen formatiert wird. Die Formatierung ist abhängig von der Syntax und der Struktur der Programmiersprache. Notepad++ kann reguläre Ausdrücke (sogenannte RegExp) in der „Suchen und Ersetzen“ Funktion verarbeiten. Ein Anwendungsfall regulärer Ausdrücke können Wildcards sein, auf die wir gleich zu sprechen kommen.
Übersicht
Der Artikel ist aufgrund der Beispiele etwas länger geworden. Mithilfe der Links gelangen Sie zu den einzelnen Punkten.
Suchen und ersetzen
Die „Suchen und Ersetzen“ Funktion kann in Notepad++ über zwei Wege erreicht werden:
- Möglichkeit:
Unter dem Punkt „Suchen“ in der Menüleiste, kann der Listeneintrag „Ersetzen …“ ausgewählt werden. Anschließend öffnet sich das gewünschte Fenster. - Möglichkeit:
Die einfachere Möglichkeit besteht darin, gleichzeitig STRG+H zu drücken. Anschließend öffnet sich auch hier das gewünschte Fenster.
Wildcards
Wildcards bezeichnen Platzhalter für andere Zeichen. In der „Suchen und Ersetzen“ Funktion in Notepad++ ist es möglich, diese zu verwenden. Im Folgenden werden die wichtigsten Wildcards aufgelistet und deren Einsatz beschrieben. Die Tabelle zeigt die Schreibweise in Notepad++. Hier werden häufig vor Verwendung einer Wildcards ein „.“ benötigt.
| Wildcard | Beschreibung |
|---|---|
| .? oder . | Ein Fragezeichen sucht nach genau einem Zeichen (Character). |
| .* | Ein Sternchen sucht nach einer beliebigen Anzahl an Zeichen (auch null). |
| [] | Es wird nur nach Zeichen gesucht, die in den eckigen Klammern stehen. Die alleinige Verwendung der eckigen Klammern entspricht keinem gültigen Ausdruck.
Zeichen: Zahlen: Beliebige lateinische Buchstaben oder beliebige Ziffern: Zeichen ausschließen: |
Quantoren
Der Verwendung von Quantoren ist optional. Sie erweitern Wildcards und erlauben es, Wiederholungen in Zeichenketten zu finden. Die Syntax lautet:
<Wildcard><Quantor>
| Quantor | Beschreibung |
|---|---|
| ? | Erweitert man eine Wildcard um ein Fragezeichen, muss dieser Ausdruck nicht vorkommen, er kann aber. |
| + | Das Pluszeichen bedeutet, dass der voranstehende Ausdruck mindestens einmal vorkommen muss, aber beliebig oft wiederholt werden darf. |
| * | Der voranstehende Ausdruck darf beliebig oft vorkommen. Anders als das Pluszeichen darf der Ausdruck auch keinmal vorkommen. |
| {n} | Der voranstehende Ausdruck muss exakt n-mal vorkommen. |
| {n,} | Der voranstehende Ausdruck muss mindestens n-mal vorkommen. |
| {n,m} | Der voranstehende Ausdruck muss zwischen n-mal und m-mal vorkommen. |
| {0,m} | Der voranstehende Ausdruck darf maximal m-mal vorkommen. |
Sucht man beispielsweise nach [ab]{2}_ erhält man: „aa“, „bb“, „ab“ und „ba“. Wildcards und Quantoren können beliebig kombiniert werden.
Metazeichen
Metazeichen haben in einem bestimmten Kontext eine besondere Bedeutung für die Verarbeitung von Zeichenketten. Bei der Verwendung von regulären Ausdrücken, wie es bei der „Suchen und Ersetzen“ Funktion von Notepad++ der Fall ist, haben folgende Metazeichen eine besondere Bedeutung:
| Metazeichen | Beschreibung |
|---|---|
| ^ | Dieses Metazeichen steht für einen Zeilen- oder String-Anfang |
| $ | Ein Dollar-Zeichen steht für ein Zeilen- oder String-Ende |
| ? + * { } | Finden bei Wildcards und Quantoren Verwendung |
| \ | Wandeln ein Metazeichen in ein „normales“ Zeichen um, um danach suchen zu können. |
| ( ) | Gruppierungen, um komplexes „Suchen und Ersetzen“ zu ermöglichen. Möchte man zwischen zwei Zeichen z. B. „<“ und „>“ einen beliebig langen Text finden und die zwei Zeichen anschließend entfernen, eignet sich die Verwendung von runden Klammern. Diese werden auch Tagged Expressions genannt. Innerhalb einer Suche können mehrere Tagged Expressions verwendet werden. Im Ersetzen-Teil wird mit den Tags \1_, \2_, usw. darauf zugegriffen. Auf erste Klammer kann dann z. B. mit dem Tag \1_ aufgerufen werden.
Der Suchausdruck könnte dann wie folgt aussehen: <(.*)>_. Es wird also nach beliebig vielen Zeichen zwischen dem Größer- und Kleiner-Zeichen gesucht. Im Ersetzen-Teil wird dann geschrieben \1_. Die Suche wird dadurch durch den Inhalt der Klammern ersetzt, also den beliebigen Zeichen. |
| | | Alternativen oder auch logisches „ODER“ |
| \n | Neue Zeile „line feed“ |
| \r | Neue Zeile „carriage return“ |
| \t | Tabulator |
| \d | Ein beliebiges Digit |
| \w | Ein beliebiger Buchstabe |
| \s | Ein Leerzeichen (Whitespace) |
| \b | Leere Zeichenkette am Wortanfang oder am Wortende |
| \B | Leere Zeichenkette, die nicht den Anfang oder das Ende eiens Wortes bildet |
Beispiel: Payload aus einem Daten-Stream erhalten
Die Suche von Notepad++ ist sehr effizient. Zeichnet man Log-Dateien einer seriellen Datenübertragung auf und sucht nach speziellen Paketen, kann diese perfekt eingesetzt werden. Nachrichtenpakete bestehen oft aus einem Start-Byte, einem Befehl, der Payload, einer Checksumme und einem Stopp-Byte.
| Start-Byte | Befehl | Paketzähler | Payload | Checksumme | Stopp-Byte |
|---|---|---|---|---|---|
| 0x01 | 0x12 | 1 Byte | 3 Byte | 2 Byte | 0x04 |
In diesem Beispiel möchten wir aus einem seriellen Daten-Stream die Payload erhalten. Jede Payload soll in einer neuen Zeile ausgegeben werden, um die Daten einfacher lesen zu können. Die Aufzeichnung schaut zunächst so aus:

Die gesamte Aufzeichnung wird nur in einer Zeile dargestellt, was sehr unleserlich ist. Wir wissen aber, dass jedes Paket mit dem Stopp-Byte 0x04 endet. Wir können deshalb das Zeichen 0x04 mit 0x04\n ersetzen. \n ist ein Line-Feed, also ein Zeilenumbruch. Notepad++ nimmt diese Sonderzeichen im erweiterten Suchmodus an. Das Ersetzen schaut wie folgt aus:
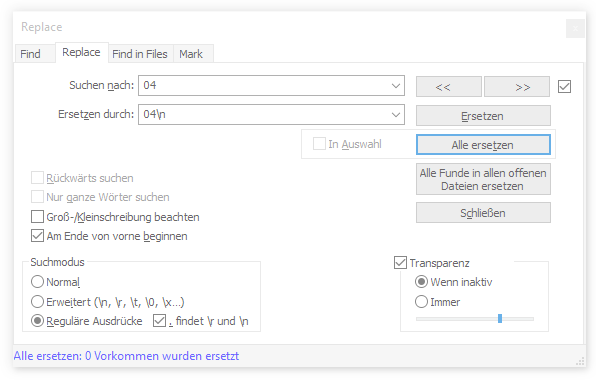
Jedes Nachrichtenpaket erscheint nun in einer neuen Zeile.

Im nächsten Schritt entfernen wir das Start-Byte, den Befehl und den Paketzähler von der Payload. Das Start-Byte und der Befehl variieren in diesem Beispiel nicht, der Paketzähler wird in jeder Zeile inkrementiert. Die Suche muss deshalb lauten 01 12 .?.?_.
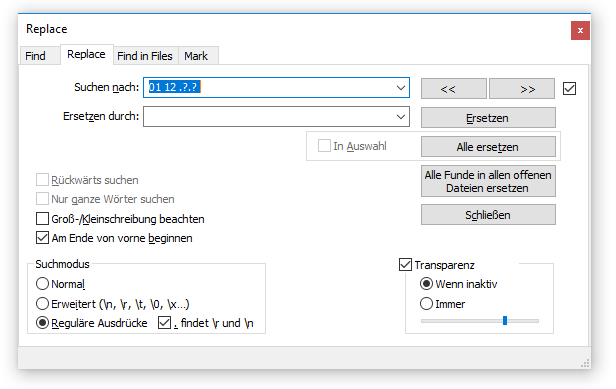
Der Nachrichtenanfang wurde nun erfolgreich entfernt:

Nun wird nur noch das Nachrichtenende entfernt. Dieses besteht aus einer 2-Byte langen Checksumme und dem Stopp-Byte. Die Suche lautet deshalb .?.? .?.? 04_. Nach diesem Schritt bleibt nur noch die Payload übrig und das gewünschte Ergebnis wurde erzielt.
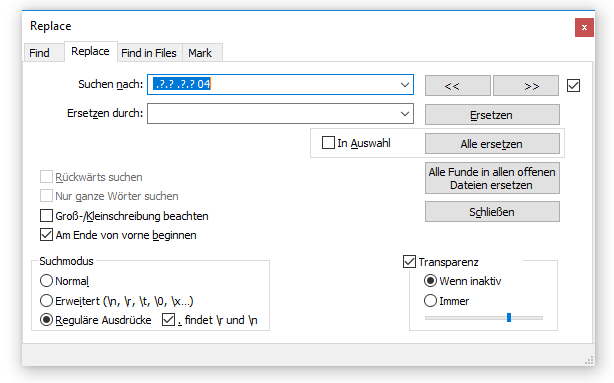
Und das Ergebnis:

Beispiel: Text innerhalb eines <div>-Tags ersetzen
In diesem Beispiel soll gezeigt werden, wie zum Beispiel der Text von HTML-Buttons einfach geändert werden kann. Auf einer Webseite sind mehrere Buttons mit der ID „test“ eingebunden. Die Texte sind unterschiedlich, sollen aber auf „mehr erfahren“ umgestellt werden. Der Code sieht wie folgt aus:

Auch wenn Zeile 2 und 3 auf den ersten Blick gleich aussehen, erkennt man, dass in Zeile 3 ein zusätzliches Leerzeichen vorhanden ist und der Text zwischen den Divs länger ist. Der Suchausdruck muss deshalb so aussehen:
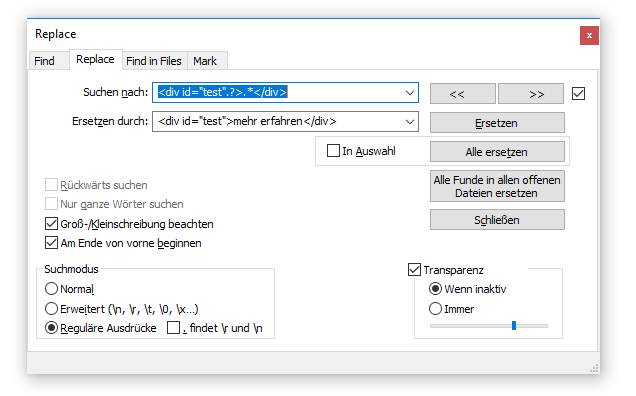
Das Resultat:

Beispiel: Unterseiten von URLs entfernen
In diesem Beispiel werden die Unterseiten von URLs entfernt. Die vorhandene Liste sieht so aus:
medtech-ingenieur.de/index.php medtech-ingenieur.de/?p=3133&preview=true medtech-ingenieur.de/blog/ medtech-ingenieur.de/dependability-in-der-medizintechnik/
Jede Unterseite kann mit dem Befehl „de/.*“ gefunden werden. Diese ersetzt man dann durch „de/“ oder „de“. Achten Sie darauf, dass der Haken bei „findet \r und \n“ nicht gesetzt ist.
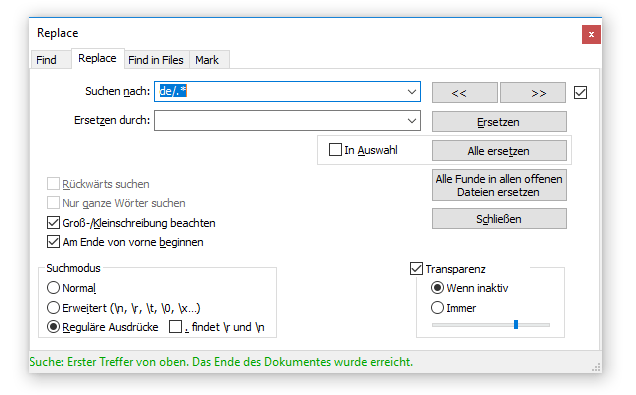
Das Ergebnis ist dann:
medtech-ingenieur.de medtech-ingenieur.de medtech-ingenieur.de medtech-ingenieur.de
Beispiel: Werte aus Klammern parsen
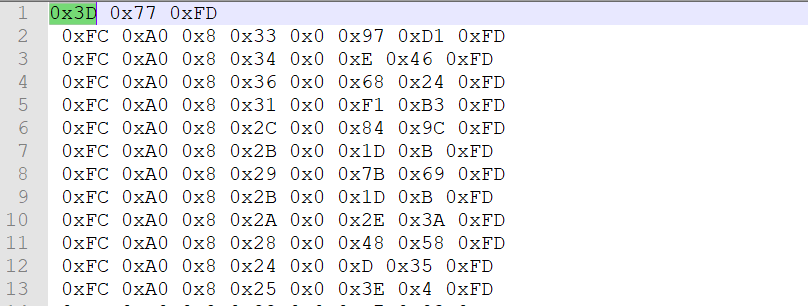
Beim Debuggen kommt es schonmal vor, lange Arrays genauer zu betrachten. Kopiert man die Werte direkt aus der Entwicklungsumgebung, werden oft die Zeilenangaben und weitere Informationen mit übertragen. Die Kopie könnte für einen Ringpuffer so aussehen (kopiert aus Android Studio):

Interessant für den Entwickler sind in diesem Fall nur die Hexadezimal-Werte. Außerdem möchte er sehen, welche Nachrichten in diesem Ringpuffer gespeichert sind. Mit nur einem Befehl schafft man es, alle Werte in einer Zeile darzustellen. Die Verwendung der runden Klammern wird auch Tagged Expression oder Gruppierung genannt. Mithilfe des Tags \1 kann auf den Inhalt der ersten Klammer in der Suche zugegriffen werden. Die Abfrage sieht wie folgt aus:
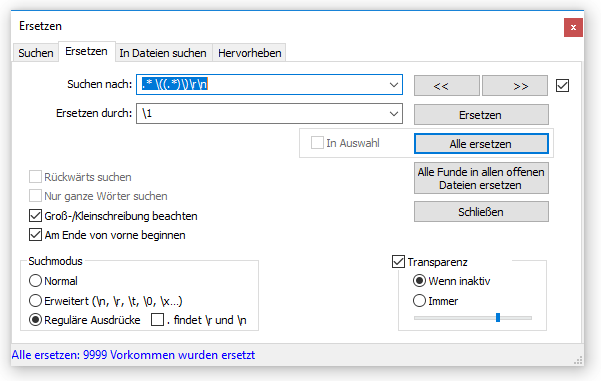
Hier ist das Ergebnis zu sehen:

Der Entwickler weiß, dass jedes Nachrichtenpaket mit 0xFD endet. Im nächsten Schritt können wir deshalb eine neue Zeile (\n) nach jedem 0xFD einfügen. Zu sehen sind dann alle Nachrichtenpakete im Ringpuffer.
Beispiel: Datum einheitlich formatieren
Eine Liste mit mehreren Daten ist unterschiedlich formatiert. Mit der „Suchen und Ersetzen“ Funktion von Notepad++ sollen alle Daten in das Format „##-##-####“ umgewandelt werden. Die Liste sieht wie folgt aus:
 Im ersten Schritt ersetzen wir alle Zeichen zwischen den Zeilen durch das Zeichen „-„. Die Verwendung von Tagged Expressions kann innerhalb der Suche mehrmals erfolgen. Auf die einzelnen Klammern kann dann durch die Tags \1, \2, usw. zugegriffen werden. Die Zahl spiegelt die Reihenfolge der Klammern wieder.
Im ersten Schritt ersetzen wir alle Zeichen zwischen den Zeilen durch das Zeichen „-„. Die Verwendung von Tagged Expressions kann innerhalb der Suche mehrmals erfolgen. Auf die einzelnen Klammern kann dann durch die Tags \1, \2, usw. zugegriffen werden. Die Zahl spiegelt die Reihenfolge der Klammern wieder.
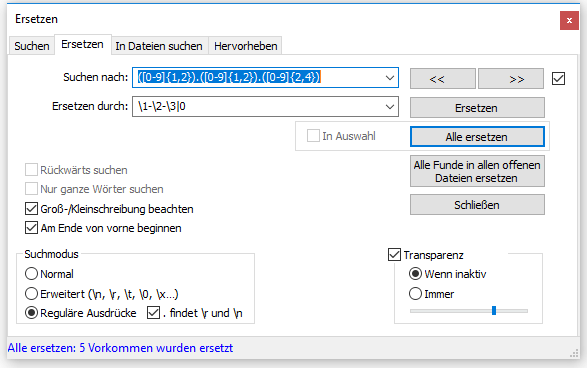
Das Ergebnis des ersten Durchlaufs sieht wie folgt aus:

Leider haben nun noch nicht alle Daten das gewünschte Format „##-##-####“. Deshalb muss ein zweiter Durchlauf mit der folgenden Suche durchlaufen werden:
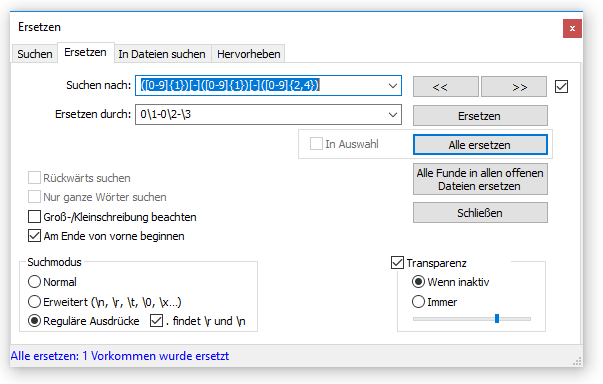
Anschließend erhält man das gewünschte Format.
Haben Sie noch Fragen oder wünschen Sie sich weitere Beispiele? Dann hinterlassen Sie doch ein Kommentar. Wir helfen Ihnen gerne weiter.
Viele Grüße
Daniel Saffer