

Im vorangegangenen Blog-Post (Architektur in Feierlaune) habe ich eine SW-Architektur beschrieben, die hilft, die Kommunikation zwischen Komponenten zu vereinfachen.
Einen Punkt habe ich in dem Zusammenhang allerdings noch nicht angesprochen: Die Datenhaltung.
Wenn Daten zwischen Modulen hin- und hergereicht werden müssen, ginge das mit der
- althergebrachten Methode – tonnenweise getter- und setter-Funktionen – gähn,
- globalen Variablen – gaanz dolle Idee, oder
- mit Hilfe von Events, denen man Daten als Payload mitgibt.
Aber spätestens dann, wenn ein Modul z.B. periodisch aktuelle Daten benötigt, scheitert man damit. Man könnte ein Event schicken, das ein anderes Modul veranlasst, die aktuellen Daten zu verschicken. Aber ehrlich: Das ist von hinten durch die Brust, oder?
Es lebe der Zentral-(Daten)friedhof
Entschuldigt, aber diese Anspielung musste einfach sein. Vielen Dank, Joesi Prokopetz, für diesen zeitlosen Text
Was spricht denn dagegen, die Datenhaltung zu zentralisieren? Die Vorteile liegen auf der Hand:
- Die Daten stünden allen Modulen zur Verfügung – das Ganze natürlich thread-safe über entsprechende Methoden.
- Die Initialisierung erfolgt an zentraler Stelle – nicht über alle möglichen Module verteilt.
- Der Zugriff mittels getter-/setter-Methoden erfolgt mit eindeutigem Identifier. Vorteil: Eine Suche über alle Module liefert schnell alle Stellen, wo auf ein Datum zugegriffen wird.
- Unittests können viel einfacher ausfallen. Denn es müssen nicht wie zuvor die zig Module gemockt werden.
- Dank C++ kann man den Zugriff auf die Daten sehr einfach typsicher gestalten.
- Der thread-safe Zugriff erfolgt „unter der Haube“ – die Caller müssen sich nicht selbst darum kümmern bzw. muss es nicht bei allen Zugriffsfunktionen implementiert werden.
Aber war’s das schon? Wenn ein Modul darüber informiert werden soll, dass sich ein Wert geändert hat, müsste ja trotzdem ein entsprechendes Event verschickt werden.
Palim-Palim
Und schon wieder ein Zitat – wer war’s?
Selbstverständlich gibt’s auch dafür eine elegante Lösung: Wenn ein Modul einen Wert im Datapool ändert, verschickt der ein Change-Event mit dem Identifier im Bauch – „läutet sozusagen mit dem Glöckchen“, wie es ein ehemaliger Kollege mal formulierte. Module, die die Ohren aufsperren (also die, die als Change-Event-Listener beim Eventdispatcher registriert sind) lesen bei Bedarf den betreffenden Wert aus dem Datapool und können mit dem neuen Wert arbeiten.
Das Konzept ist – wie so oft – nicht neu. Im Embedded Kontext ist es stark vereinfacht und hat mit einem Data Warehouse nur noch konzeptuell zu tun. Ich selbst habe das Konzept in Verbindung mit Change-Events schon vor ca. 20 Jahren kennengelernt (3SOFT bzw. EB Graphics Target Framework – gibt’s leider inzwischen nicht mehr).
In Abbildung 1 „holt“ sich eine Softwarekomponente eine Referenz auf ein Datapool-Element IValue und ändert den Wert via IValue::set(). Diese Funktion teilt dem Datapool mit, dass sich der Wert des Datapool-Items mit der zugehörigen ID geändert hat. Der lässt sich von der EventFactory ein ChangeEvent mit der ID erzeugen und übergibt es dem EventDispatcher.
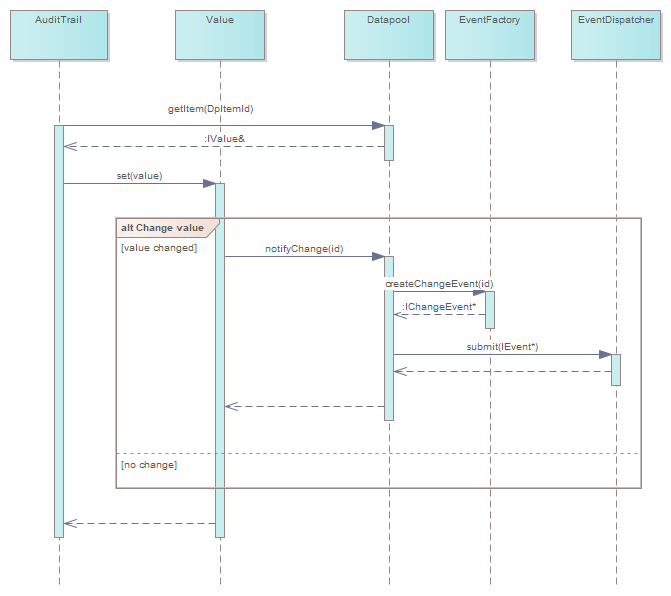
Und jetzt?
Basierend auf den zwei einfachen Konzepten (Eventsystem, Datapool) kann man komplexe Software erstellen – auch auf kleinen Embedded Systemen. Derzeit entwickeln wir eine neue Software für einen Defibrillator in dem wir genau diese Architektur sehr erfolgreich einsetzen.
Code-Generatoren sorgen dafür, dass Source-Code mit Event-/Datapool-Enums etc. immer konsistent sind – diesen Code per Hand zu klopfen ist – wie der Frange sagt – „Dööderles“-Arbeit und äußerst fehlerträchtig. Aber das Thema Code-Generierung ist einen eigenen Blogpost wert.
Brauchen Sie Unterstützung beim Design einer Software-Architektur oder bei der Entwicklung von Embedded Software? Dann wenden Sie sich gerne an uns. Unsere erfahrenen MEDtech Ingenieurinnen und Ingenieure helfen ihnen gerne dabei ihr Medizinprodukt zu entwickeln oder offene Fragen zu klären.