
Was ist das Problem?
Wenn wir Embedded Software entwickeln ist die Wunschvorstellung das wir nach V-Modell spezifizieren, implementieren, integrieren, testen und anschließend ausliefern. In realen Projekten sieht das aber natürlich etwas anders aus. In der Regel wird Software inkrementell entwickelt. Während der Entwicklung gibt es immer Zwischenstände mit unterschiedlichen Features, die unterschiedlich ausgereift sind. Wünschenswert wäre es natürlich, dass ausschließlich Hardware mit getesteten, stabilen Softwareversionen den Schreibtisch des Entwicklers verlässt. Leider ist dies bedingt durch den Projektplan und die anderen Projektteilnehmer oft nicht möglich. So kann es zum Beispiel passieren, dass der Hardwareentwickler schnell eine Software für den EMV Test benötigt oder der Projektleiter dem Kunden unbedingt morgen die neue GUI vorführen möchte. Oft werden die so entstandenen unreifen Versionen auf diese Weise im ganzen Haus verteilte oder gehen sogar an den Kunden raus. Nach einigen Wochen kommt dann auf einmal Hardware zurück auf den Tisch des Softwareentwicklers, mit dem Hinweis, dass bei der Benutzung ein Problem aufgetreten ist.
In der Regel wird der Projektleiter dem Entwickler die Aufgabe erteilen, dieses Problem zu untersuchen. Wenn der Entwickler nun nachvollziehen kann, um welchen Softwarestand es sich handelt, kann er eventuell darauf verweisen, dass es sich um einen Bug handelt, der bereits behoben wurde. Oft ist die Zuordnung von Embedded Softwareständen aber gar nicht so einfach.
Um das Problem zu lösen, gibt es in der Regel den Ansatz für jede Hardware, die im Umlauf ist, den aktuellen SW Stand zu verzeichnen. So kann man z. B. über ein Ticketsystem oder im Projektwiki Seiten anlegen, in dem jeder Hardware ein aktueller Standort und eine Software Versionsnummer zugeordnet wird. Solche Hardware Tracker klingen zunächst gut. Denkt man aber genauer darüber nach, schreit dieses Vorgehen geradezu danach, das auf diese Weise Fehler passieren. Es geschieht schneller, als man denkt, dass jemand außerhalb der SW, den Entwickler darum bittet, mal eben den neusten Stand auszuspielen. Oder vorher sogar noch eine Änderung durchzuführen.
So hat der SW Entwickler immer das Problem, wenn er die SW Version zuordnen will, dass er folgende Fragen nicht beantworten kann:
- Ist die SW Version, die im Tracker steht wirklich korrekt?
- Entspricht die Version wirklich 1:1 einem bestimmten Stand im Repository oder gibt es lokale Änderungen?
- Mit welcher Build Konfiguration wurde die SW gebaut?
Wie kann man das Problem lösen?
Um dem Problem zu begegnen, liegt es nahe, die SW selber mit einem Versionsstempel zu versehen. Der erste Impuls, wenn man seine Software versionieren möchte, ist eine Konstante anzulegen. Das kann z. B. so aussehen:
#define REVISION "1.01"
Das ist von der Idee her schon nicht schlecht. Man sollte sich aber im Klaren sein, dass wenn bei manueller Versionierung immer auf die oben beschriebenen Probleme stößt. Die Versionierung sollte also besser automatisch erfolgen. Ein einfaches Beispiel möchte ich hier, am Beispiel einer in Eclipse entwickelten Mikrocontroller Software kurz vorstellen:
Schritt 1: Die Version des Repositorys in die Software bekommen
Am besten lässt sich der Stand einer Software nachvollziehen, in dem man keine klassische Versionsnummer, sondern den Stand des Repositorys verwendet. Das kann z. B. die SVN Revision oder der GIT hash sein. In Eclipse lässt sich die Revision relativ leicht in einer Konstanten verwenden. Schauen wir uns das mal am Beispiel von SVN an:

Mit dem Markierten Makro, erzeugen wir einen konstanten String, der sich aus folgenden Punkten zusammensetzt
- ${ConfigName}: Das ist der Name unserer Buildkonfiguration. In unserem Fall „Debug“
- $(shell svnversion -n ‚ .\..‘): Das ist die aktuelle SVN Revision des Projektordners.
- shell: ausführen eines Kommandozeilenbefehls
- svnrevision: Gibt die SVN revision eines Ordners zurück. Dafür muss unser System natürlich diesen Befehl verstehen. Wer jetzt denkt, es reicht Tortoise SVN auf seinem PC installiert zu haben den muss ich leider enttäuschen. Tortoise mag entsprechende Kommandozeilenbefehle haben, allerdings unterstützt es nicht die klassischen SVN Kommandozeilenbefehle. Am einfachsten erhalte ich diese in dem ich den kostenlosen „SlikSVN Windows client“ installiere und in den Systemumgebungsvariablen unter „PATH“ den „bin“ Ordner von SlikSVN anlege.
- „.\..“: Das ist der Pfad des Projektordners, relativ zum Output Ordner meiner Buildkonfiguration. Also in diesem Fall vom Ordner „Debug“ aus gesehen. Also der Ordner in dem die Artefakte der Debug-Konfiguration nach dem Bauen meiner Software landen.
Habe ich nun dieses Makro angelegt, erhalte ich beim Debuggen für das Makro SVN_REV folgenden Wert:
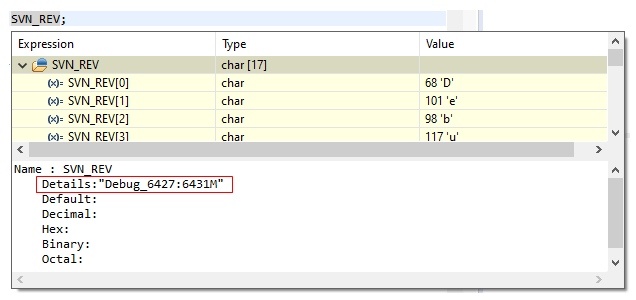
Aber was bedeutet „6427:6431M“? Hierbei handelt es sich um den Bereich der SVN Revisionen. Das heißt, ich habe in meinem Projektordner Dateien der SVN Revisionen 6427 bis 6431. Würde ich meinen lokal ausgecheckten SVN Ordner auf eine bestimmte Revision zurücksetzen, stünde hier einfach nur eine Zahl. Das „M“ bedeutet, dass es lokale Änderungen in meinem Projektordner gibt. Ich weiß also mit diesem String fast alles, was ich wissen muss, um die Herkunft der Software zuzuordnen. Das ist schon ziemlich cool, es geht aber noch besser.
Schritt 2: Eine feste Stelle im Speicher definieren
Mit Schritt 1 habe ich sichergestellt das die Revision in meiner Software immer bekannt ist. Ich kann diesen String also z. B. auf dem Display anzeigen lassen oder über eine Kommunikationsschnittstelle abfragen. Wenn mir das reicht, kann man hier aufhören. Ich kann das ganze aber noch verbessern, indem ich dem Versionsstring eine feste Nummer im Speicher zuweise. So kann diese z. B. auch durch den Bootloader ausgelesen werden.
Für die Versionsnummer lege ich zunächst im Linker-File einen Speicherbereich im Flash an:
/* Memories definition */
MEMORY
{
RAM (xrw) : ORIGIN = 0x20000000, LENGTH = 160K
FLASH (rx) : ORIGIN = 0x08000000, LENGTH = 262140
VER (rx) : ORIGIN = 0x0803FFE0, LENGTH = 28
}
Und weiter unten:
/* SVN revision goes here */
.app_ver_str :
{
KEEP(*(.app_ver_str))
} > VER
Anschließend muss ich in meinem Code folgende Zeile einfügen.
const char __attribute__((section(".app_ver_str"))) VER[] = SVN_REV;
Mit dieser Zeile schreibe ich meine in Schritt 1 angelegte Konstante beim linken automatisch in die section „app_ver_str“. Diese habe ich im Speicherbereich „VER“ platziert. Sobald ich also meine Software neu baue, platziert der Linker automatisch meinen Versionsstring an Adresse 0x80FFE0. Wenn man das überprüfen möchte, reicht ein Blick in die .hex Datei:
![]()
Wenn wir das Ganze in einen Hex-zu-Ascii-Converter eingeben, von denen es im Internet jede Menge gibt, erhalten wir wieder unseren Revisionsstring „Debug_6427:6431M“. Das hat den angenehmen Nebeneffekt das ich auch .hex Dateien, welche eventuell im Umlauf sind, zuordnen kann, indem ich diese einfach mit einem Editor öffne.
Fazit
Es gibt viele Gründe seine Software automatisch zu versionieren. Wer ein neues Softwareprojekt aufsetzt, sollte möglichst schnell etwas Entsprechendes einrichten, bevor Software im Umlauf ist, deren Stand nicht mehr zugeordnet werden kann. Das hier gezeigte Vorgehen lässt sich natürlich auch auf nicht-Eclipse-basierte IDEs wie Keil oder IAR übertragen. Außerdem lässt sich das ganze ebenso gut (wenn nicht besser) mit GIT umsetzen.