

In the previous blog post (Architecture in a celebratory mood) I have described a software architecture that helps to simplify communication between components.
However, there is one point I have not yet addressed in this context: data storage.
If data needs to be passed back and forth between modules, this could be done with the
- traditional method – tons of getter and setter functions – yawn,
- global variables – really great idea, right
- using events that contain data as payload.
But at the very latest, when a module, for example, periodically requires updated data, this approach fails. You could send an event that causes another module to send the updated data. But honestly, that's a bit of a ploy, isn't it?
Long live the central (data) cemetery
Sorry, but this reference just had to be made. Thank you, Joesi Prokopetz, for this timeless text.
What's the argument against centralizing data storage? The advantages are obvious:
- The data would be available to all modules – all thread-safe, of course, via appropriate methods.
- Initialization takes place centrally – not distributed across all possible modules.
- Access via getter/setter methods is done with a unique identifier. Advantage: A search across all modules quickly yields all locations where a data item is accessed.
- Unit tests can be much simpler, as there's no need to mock up countless modules as before.
- Thanks to C++, access to data can be made very easy and type-safe.
- Thread-safe access is implemented “under the hood” – callers do not have to worry about it themselves, and it does not have to be implemented for all access functions.
But is that all? If a module needs to be informed that a value has changed, a corresponding event would still have to be sent.
Palim-Palim
And another quote – who was it?
Of course, there's an elegant solution for this too: When a module changes a value in the data pool, it sends a change event with the identifier in its belly—"ringing the bell, so to speak," as a former colleague once put it. Modules that listen (i.e., those registered as change event listeners with the event dispatcher) read the relevant value from the data pool when needed and can work with the new value.
The concept—as is often the case—isn't new. In an embedded context, it's greatly simplified and only has a conceptual connection to a data warehouse. I first encountered the concept in connection with change events about 20 years ago (3SOFT or EB Graphics Target Framework—unfortunately no longer exists).
In Figure 1, a software component “gets” a reference to a data pool element IValue and changes the value via IValue::set()This function informs the data pool that the value of the data pool item with the associated ID has changed. The data pool then generates a ChangeEvent with the ID from the EventFactory and passes it to the EventDispatcher.
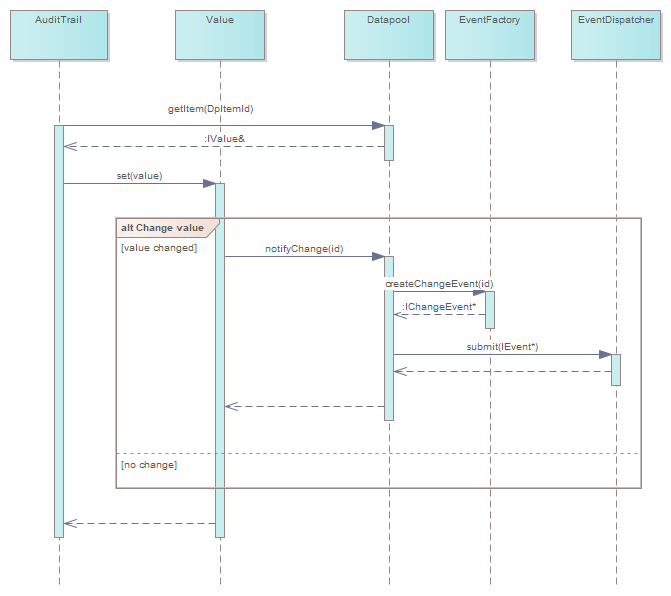
And now?
Based on these two simple concepts (event system, data pool), complex software can be created – even on small embedded systems. We are currently developing new software for a defibrillator in which we are successfully using this very architecture.
Code generators ensure that source code with event/data pool enums, etc., is always consistent. Typing this code by hand is, as Frange says, a "dumbass" job and extremely error-prone. But the topic of code generation is worth a blog post of its own.
Do you need support with designing a software architecture or developing embedded software? Then please contact us. Our experienced MEDtech engineers will be happy to help you develop your medical device or clarify any outstanding questions.