
What is the problem?
When we develop embedded software, the ideal is that we specify, implement, integrate, test and then deliver according to the V-model. In real projects, however, things are somewhat different. Software is usually developed incrementally. During development, there are always intermediate stages with different features that have varying levels of maturity. It would of course be ideal for only hardware with tested, stable software versions to leave the developer's desk. Unfortunately, this is often not possible due to the project plan and the other project participants. For example, it can happen that the hardware developer quickly needs software for EMC testing, or the project manager absolutely wants to demonstrate the new GUI to the customer tomorrow. The resulting immature versions are often distributed throughout the company in this way or even sent to the customer. Then, after a few weeks, the hardware suddenly makes its way back to the software developer's desk with a note that a problem occurred during use.
Typically, the project manager will assign the developer the task of investigating this issue. If the developer can then determine the software version, they may be able to point out that it's a bug that has already been fixed. However, assigning embedded software versions is often not that easy.
To solve this problem, the usual approach is to record the current software version for every piece of hardware in circulation. For example, you can create pages via a ticket system or in the project wiki where each piece of hardware is assigned a current location and a software version number. Such hardware trackers sound good at first. But upon closer consideration, this approach practically invites errors. It's quicker than you think that someone outside the software department will ask the developer to quickly deploy the latest version, or even to make a change beforehand.
So the SW developer always has the problem when he wants to assign the SW version that he cannot answer the following questions:
- Is the software version listed in the tracker really correct?
- Does the version really correspond 1:1 to a specific state in the repository or are there local changes?
- Which build configuration was used to build the software?
How can the problem be solved?
To address this problem, it makes sense to add a version stamp to the software itself. The first thing you should do when you want to version your software is to create a constant. This might look something like this:
#define REVISION "1.01"
The idea isn't bad. However, one should be aware that manual versioning will always run into the problems described above. Therefore, versioning should be done automatically. I'd like to briefly present a simple example here, using a microcontroller software developed in Eclipse:
Step 1: Get the repository version into the software
The best way to track the status of a software is to use the repository version instead of a traditional version number. This could be, for example, the SVN revision or the GIT hash. In Eclipse, the revision is relatively easy to use as a constant. Let's look at this using SVN as an example:

With the marked macro, we create a constant string that consists of the following points
- ${ConfigName}: This is the name of our build configuration. In our case, "Debug"
- $(shell svnversion -n ‚ .\..'): This is the current SVN revision of the project folder.
- shell: execute a command line command
- svnrevision: Returns the SVN revision of a folder. Of course, our system must understand this command for this to work. Anyone who thinks it's enough to have Tortoise SVN installed on their PC will be disappointed. Tortoise may have the appropriate command-line commands, but it doesn't support the classic SVN command-line commands. The easiest way to get these is to install the free "SlikSVN Windows client" and create the SlikSVN "bin" folder in the system environment variables under "PATH."
- ".\..": This is the path of the project folder relative to the output folder of my build configuration. In this case, from the "Debug" folder. This is the folder where the debug configuration artifacts end up after building my software.
Once I have created this macro, I get the following value for the SVN_REV macro when debugging:
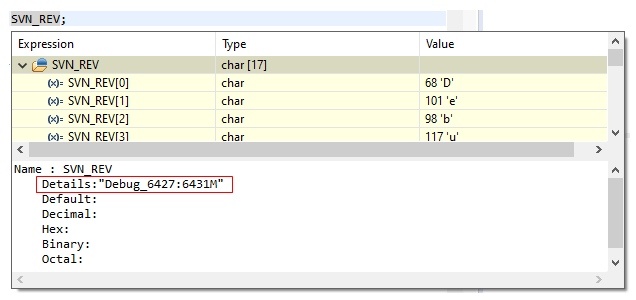
But what does "6427:6431M" mean? This is the SVN revision range. This means that I have files from SVN revisions 6427 to 6431 in my project folder. If I were to reset my locally checked-out SVN folder to a specific revision, it would simply show a number. The "M" means that there are local changes in my project folder. So, with this string, I know almost everything I need to know to determine the origin of the software. That's pretty cool, but it can be even better.
Step 2: Define a fixed location in memory
With step 1, I ensured that the revision is always known in my software. This means I can display this string on the screen, for example, or query it via a communication interface. If that's enough for me, I can stop here. However, I can improve the whole thing by assigning a fixed number in memory to the version string. This way, it can also be read by the bootloader, for example.
For the version number, I first create a memory area in the flash in the linker file:
/* Memories definition */ MEMORY { RAM (xrw) : ORIGIN = 0x20000000, LENGTH = 160K FLASH (rx) : ORIGIN = 0x08000000, LENGTH = 262140 VER (rx) : ORIGIN = 0x0803FFE0, LENGTH = 28 }
And further down:
/* SVN revision goes here */ .app_ver_str : { KEEP(*(.app_ver_str)) } > VER
Then I have to add the following line to my code.
const char __attribute__((section(".app_ver_str"))) VER[] = SVN_REV;
With this line, I automatically write the constant I created in step 1 to the "app_ver_str" section during linking. I placed this section in the "VER" memory area. So, as soon as I rebuild my software, the linker automatically places my version string at address 0x80FFE0. If you want to verify this, just look at the .hex file:
![]()
If we enter the whole thing into a hex-to-ASCII converter, of which there are plenty available online, we get our revision string "Debug_6427:6431M" again. This has the pleasant side effect that I can also assign .hex files that might be in circulation by simply opening them with an editor.
Conclusion
There are many reasons to automatically version your software. Anyone setting up a new software project should set something up as quickly as possible, before software whose version can no longer be assigned is in circulation. The approach demonstrated here can, of course, also be applied to non-Eclipse-based IDEs like Keil or IAR. Furthermore, the whole process can be implemented just as well (if not better) with GIT.